ChinAI #341: Big Tech v. the Chinese Government in New AI Companion Regs
China’s new regulations matter but not for the reasons you think
Jan 5
Greetings from a world where…
Slow Horses is so good
…As always, the searchable archive of all past issues is here. Please please subscribe here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay support access for all AND compensation for awesome ChinAI contributors).
Feature Translation: An Initial Look at Companion AI Regulatory Pathways — Big Tech Firms are Sleepless
Context: Here’s a question I often hear on panels: Can Chinese companies actually resist the government, given, you know, uh, the system over there? It’s a simple but essential question. And I would wager that a lot of people who label themselves as “China watchers” would give either the wrong answer or an incoherent one. Don’t worry though: they’ve read one article about those party committees, so we can end the conversation there!
To answer this question, let’s work through two concrete examples. First, look at the pushback from businesses against China’s social credit system. The Chinese government declared ambitions to create a comprehensive dataset that integrates data from businesses with “credit” information on individuals. Yet, given the importance of proprietary datasets, why would companies share their data with government departments (which have been lax about data security measures in the past)? According to FT reporting, Alibaba and Tencent refused to give over customer loans data to a national credit scoring scheme. As Martin Chorzempa and Samm Sacks conclude, “The lack of even basic data sharing is one of the most overlooked roadblocks to constructing the social credit system.”
Next, China’s AI regulation-making process gives us another opportunity to explore the sometimes contentious relationship between the Chinese government and companies. On December 27, the Cyberspace Administration of China released draft measures on human-like interactive AI services (English translation from China Law Translate). The measures attempt to address the risks of companion AI, especially for minors.
However, some of the specific planks will likely draw resistance from companies. As noted by the excellent Geopolitechs blog — written by an analyst at a Chinese big tech company — the draft has “caused heated discussion among China’s AI community and drawn commentary from independent media voices.” This week’s translation features one of these critical commentaries (link to original Chinese) from a WeChat public account [数据何规] run by Chen He, a data compliance manager at a large Chinese securities firm.
Key Takeaways: Acknowledging that human-like interactive AI is a high-risk area, Chen He writes, “However, the Measures impose very high compliance obligations on companies, and I believe that AI companies will collectively raise concerns.”
- One likely area of pushback pertains to how AI companies obtain consent to exploit user data for model training. This matters. As He notes, “High-quality training data is already scarce, and user interaction feedback is an important reference for fine-tuning and optimizing models.” Currently, in accordance with existing national standards (specifically, the “basic security requirements for genAI services” standard ), companies can have a default setting that permits utilization of user data for training purposes, with an option for users to go out of their way and disable it — as the standard states, as long as users can “reach the option from the main service interface in no more than 4 clicks.”
- Article 15 of these latest draft measures would change that. It reads: “Except as otherwise provided by laws and administrative regulations, or where users’ separate consent has been obtained, providers must not use users’ interaction data or sensitive personal information in model training.” The key phrase here is “separate consent,” which differs from a default setting of permissive use. To illustrate this point, He includes a screenshot of Doubao’s training data opt-out interface (pictured below) and asks: If this permission request for your user data popped up immediately when you entered the app, would you allow ByteDance to mine your user data?
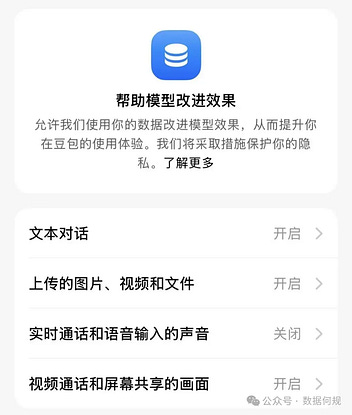
Second, if past AI regulations are any guide, the final version of these measures will look meaningfully different. Chen He writes, “It is anticipated that, like the ‘Interim Measures for the Management of Generative Artificial Intelligence Services,’ the final version will have significant changes compared to the draft.
- Many people have singled out the companion AI regulation’s provision that obligates AI developers to use training data that reflects “core socialist values” (Article 6). I would predict that this gets watered down in later versions, as this degree of scrutiny on training data will be very difficult to enforce and implement.
- Again, we can trace this back-and-forth dispute through the development of past regulations on generative AI services. In the initial draft, released in April 2023, the Chinese government mandated that AI developers ensure the “veracity, accuracy, objectivity, and diversity” of their training data. In the final draft, the measures were softened considerably, as AI developers only needed to “employ effective measures to increase the quality of training data, and increase the truth, accuracy, objectivity, and diversity of training data.”
- The aforementioned basic security requirements standard also went through a similar process, as documented in ChinAI #271: Key Chinese GenAI Security Standard Changelog. For example, the initial version demanded that a“blacklist of corpus sources should be established, and data from blacklisted sources should not be used for training.” Yet, in later drafts, this blacklist requirement was dropped.
To conclude, permit me a brief meditation on the opening question. Why is it so hard for us to even conceive of the possibility that Chinese firms pursue interests that diverge from the government? I don’t have the answers here. And, of course, contentious business-state relations will look different in an authoritarian context. I do know this: If you’re a data compliance manager or a policy strategist at a Chinese company, the answer is obvious — pushing back against the government is just part of the job. Are we reading them?
One starting point is this week’s FULL TRANSLATION: An Initial Look at Companion AI Regulatory Pathways — Big Tech Firms are Sleepless
ChinAI Links (Four to Forward)
Should-read: AI Futures Project update to AI 2027
Last February, I rebutted Anthropic CEO Dario Amodei’s post that argued DeepSeek’s success only reinforced the need for the U.S.’s export control policy. For Dario and many others that shaped the Biden administration’s October 2022 controls, U.S.-China competition was a two-year sprint to artificial superintelligence, which was always only two years away (from being two years away). As Dario wrote in January 2025, “Making AI that is smarter than almost all humans at almost all things…is most likely to happen in 2026-2027).”
I argued instead: “It’s really important to note Dario’s assumed one-to-two year timeline. I’ve been in governance of AI circles since 2017. In that time, I’ve consistently heard some iteration of: AGI is two years away! It’s the Bruno Caboclo of technologies: always two years away from being two years away.”
Shortly after Dario’s post, a group of researchers released an AI 2027 forecast that predicted the emergence of generally superintelligent AIs in the same two-year window as Dario. Now, not even a year later, they’ve updated their timelines, and guess what? Median timelines for artificial superintelligence have been pushed back to 2034. We’re seven years away from being two years away.
Should-read: The Coder ‘Village’ at the Heart of China’s A.I. Frenzy
Way back in May 2020, I highlighted Hangzhou’s “AI Town” in a Nesta essay that underscored the role of provincial and local governments in implementing China’s AI strategy:
Eleven days before the AIDP was released, on 9 July 2017, the Hangzhou AI Town (杭 州人工智能小镇) opened for business, with the mission to link together e-commerce company Alibaba, Zhejiang University, graduates returning from overseas and local businesses in an AI cluster…The Hangzhou AI Town’s 2019 audit report, which provides a breakdown of funding allocations, offers some preliminary indications of the town’s progress. It disbursed 43 million RMB in funding in 2019, separated into research and development (R&D) funds, subsidies for office fees and cloud services funds.
It was fun to revisit Meaghan Tobin’s NYT piece, from summer 2025, on the “villagers” who live in this town. It’s an immersive article, with some great nuggets:
Founders described choosing between two paths for their companies’ growth: Take government funding and tailor their product to the Chinese market, or raise enough money on their own to set up offices in a country like Singapore to pitch foreign investors. For most, the first was the only feasible option.
Should-read: AI toys are all the rage in China—and now they’re appearing on shelves in the US too
For MIT Tech Review, Caiwen Chen covers China’s growing AI toy sector, which is “growing faster than almost any other branch of consumer AI.” This provides essential background for some of the provisions regarding minors in the companion AI regulations.
Should-read: The Race for Global Domination in AI
I provided some comments for Michael Schuman’s Atlantic article on the U.S.-China AI competition.
Thank you for reading and engaging.
*These are Jeff Ding’s (sometimes) weekly translations of Chinese-language musings on AI and related topics. Jeff is an Assistant Professor of Political Science at George Washington University.
Check out the archive of all past issues here & please subscribe here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay for a subscription will support access for all).
Also! Listen to narrations of the ChinAI Newsletter in podcast format here.
Any suggestions or feedback? Let me know at chinainewsletter@gmail.com or on Twitter at @jjding99
© 2026 Jeffrey Ding